


Ученые из лаборатории исследований искусственного интеллекта (ИИ) Tinkoff Research открыли новый алгоритм для обучения ИИ. Новый метод, названный SAC-RND, обучает роботов в 20 раз быстрее и на 10% качественнее всех существующих аналогов — такие результаты показало тестирование метода на робототехнических симуляторах.
Обучение искусственного интеллекта — процесс, требующий больших ресурсов: прежде всего, вычислительных мощностей, финансовых затрат и времени. Его оптимизация позволит ускорить развитие всех областей, в которых используются ИИ-агенты, например робототехники.
SAC-RND может повысить безопасность беспилотных автомобилей, упростить логистические цепочки, ускорить доставку и работу складов, оптимизировать процессы горения на энергетических объектах и сократить выбросы вредных веществ в окружающую среду. Открытие не только улучшает работу узкоспециализированных роботов, но и приближает ученых к созданию универсального робота, способного в одиночку выполнять любые задачи.
Результаты исследования были признаны мировым научным сообществом и представлены на Международной конференции по машинному обучению (ICML), которая в этом году прошла в 40-й раз в Гонолулу, Гавайи, с 23 по 29 июля. Это одна из трех крупнейших конференций в мире, оказывающих наибольшее влияние на исследования в сфере машинного обучения и искусственного интеллекта.

Суть открытия
Сегодня одно из наиболее перспективных видов обучения ИИ — обучение с подкреплением (RL), вдохновленное процессами человеческого обучения и отличающееся высоким уровнем эффективности. RL позволяет роботам учиться методом проб и ошибок, адаптироваться в сложных средах и изменять поведение на ходу. Обучение с подкреплением может использоваться во всех сферах: от регулирования пробок на дорогах до рекомендаций в социальных сетях, которые предлагают пользователю контент, основанный на его предпочтениях.
Ранее считалось, что использование случайных нейросетей (алгоритмов для последовательного и автоматического принятия решений, RND) не подходит для офлайн-обучения роботов с подкреплением. Изучив прежние работы, связанные с использованием RND, исследователи из Tinkoff Research обнаружили недостатки в проведенных экспериментах и полученных выводах.
При использовании метода RND участвуют две нейросети — случайная и основная, которая пытается предсказать поведение первой. Важное свойство каждой нейросети — ее глубина: количество слоев, из которых она состоит. У основной сети не должно быть меньше слоев, чем у случайной, иначе она не сможет смоделировать ее поведение, что приведет к нестабильности или невозможности обучения. В Tinkoff Research обнаружили, что в предыдущих работах на тему использования случайных нейросетей в обучении с подкреплением размер случайной сети составлял четыре слоя, а размер основной — два.
Использование неправильных размеров сетей привело научное сообщество к ошибочному выводу, что метод RND не умеет дискриминировать (классифицировать) данные — отличать действия, которые были в датасете, от тех, что там не было. Исследователи из Tinkoff Research исправили глубины сетей, сделав их эквивалентными, и быстро обнаружили, что при таких настройках методу удается различать данные.
Следующим шагом стала оптимизация метода. Роботы научились приходить к эффективным решениям благодаря использованию механизма слияния, основанного на модуляции сигналов и их линейном отображении. В предыдущих работах на тему RND сигналы не подвергались дополнительной обработке.
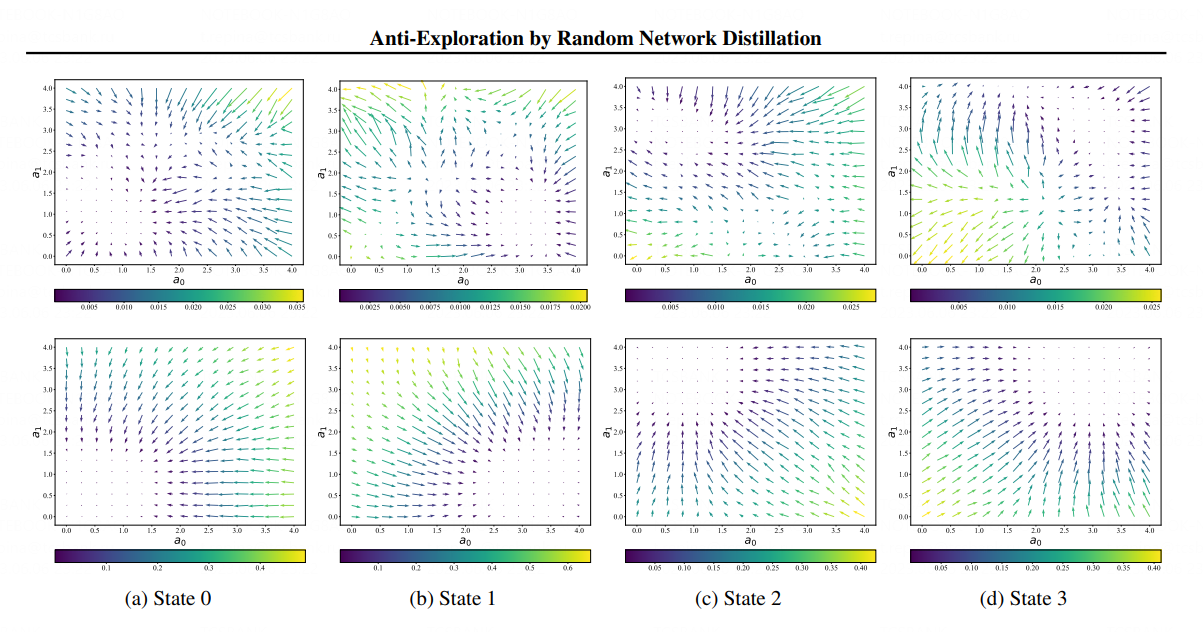
Визуализация принятия решения роботами, обученными с помощью разных алгоритмов. 4 рисунка сверху — предыдущие методы, основанные на RND, 4 рисунка снизу — метод SAC-RND. Стрелки на изображении должны вести робота в одну точку — они указывают направление к правильному действию. Метод Tinkoff Research во всех случаях стабильно приводит робота в нужную точку
Метод SAC-RND был протестирован на робототехнических симуляторах и показал лучшие результаты при меньшем количестве потребляемых ресурсов и времени. Открытие поможет ускорить исследования в области робототехники и обучения с подкреплением, поскольку оно снижает время получения устойчивого результата в 20 раз и является важным шагом на пути к созданию универсального робота.
Лаборатория исследований ИИ Tinkoff Research
Tinkoff Research — это одна из немногих российских исследовательских групп, которая занимается научными исследованиями внутри компании, а не на базе некоммерческой организации.
Ученые из Tinkoff Research исследуют наиболее перспективные области ИИ: обработку естественного языка (NLP), компьютерное зрение (CV), обучение с подкреплением (RL) и рекомендательные системы (RecSys). По результатам экспериментов они пишут научные статьи для наиболее авторитетных научных конференций: NeurIPS, ICML, ACL, CVPR и других.
За два года существования команды более 13 статей были приняты на крупнейшие конференции и воркшопы в области ИИ. Научные работы Tinkoff Research цитируются учеными из университетов Беркли и Стэнфорда, а также исследовательского проекта Google по изучению искусственного интеллекта Google DeepMind.
Команда курирует исследовательскую лабораторию Тинькофф на базе МФТИ и помогает талантливым студентам совершать научные открытия.